- Interpreter
- Compiler
- Scanner
- Parser
- Lexeme
- Token
- Nondeterministic Finite Automaton
- Deterministic Finite State Machine
- Regular Expression
- Transducer
- Context-Free Grammar
- Language
- Parse Tree
- Top-Down Parsing
- Bottom-Up Parsing
- Terminal
- Non-terminal
- Production
- Derivation
- Left-Most Derivation
- Right-Most Derivation
- Ambiguity (in a grammar)
- Precedence
- Associativity
- Right Associativity
- Left Associativity
- Recursive Grammar
- Left Recursive Grammar
- Left Factoring
- Recursive Descent Parsing
- Predictive Parsing
- First Set
- Follow Set
- LL(1) Parser
- Parse Table
- Shift in LR Parser
- Reduce in LR Parser
- Shift-Reduce Conflict
- Reduce-Reduce Conflict
- Precedence Declaration
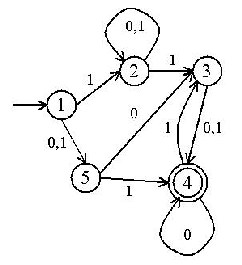
- Create a deterministic finite state machine to accept legal strings (and only legal strings).
- Create a nondeterministic finite state machine to accept legal strings (and only legal strings).
- Create a regular expression to accept legal strings (and only legal strings).
- 1* 0 ( 1* 0 1* 0 1* ) *
- {+ abc | def }+
- 10* 1 | 01* 0
(a | b | c) * d (e+) f
into a corresponding non-deterministic finite state machine.
E -> E + E | E - E | E * E | E / E | - E | int
Show two different left-most derivations of the string int + int * int / int. Also show the corresponding parse trees. What does this tell you?
E -> E + E | E - E | E * E | E / E | - E | int
so that all of the binary operations are left associative and the precedence of the operators is (highest to lowest): +,* (highest), /, - (middle), unary - (lowest)?
A -> A + B | A - B | B
B -> C * B | C / B | C
C -> ( A ) | int
S -> A $
A -> - A B | id C
B -> - B | ""
C -> "" | . id
S -> A $
A -> - A B | id C
B -> - B | ""
C -> "" | . id