In this lab you will be implementing the backpropagation algorithm (see the text book and class notes for more details on this algorithm). Your team assignments can be found here.
In this assignment, you will be implementing a simple form of backpropagation network which we will call a multi-layer perceptron (or MLP for short). Your program will need to be able to construct and learn a neural network using backpropagation for different situations. To construct the network you will set various parameters, some of which will be contained in the code and a few that you will need to add yourself. For this code we will assume that your networks are limited to feed-forward networks with no cycles in the weights. Furthermore, you will assume that every hidden and output unit will be connected to a bias unit. For the remaining connectivity of the network you will use the MLP model. In this model, a network is viewed as containing several layers. Each network will have one input layer (corresponding to the input features) and one output layer (corresponding to the output features). There will also be some number of hidden layers (possibly 0) each with a number of units. For example, consider the following network:
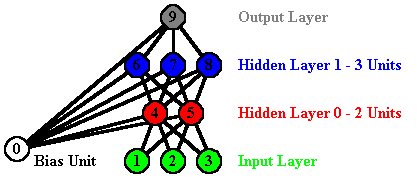
This network has an input layer with three units, an output layer with one unit and two hidden layers (the first with two units and the second with three). In an MLP, all of the units at one layer are always connected to all of the units in the previous layer (so, in the network shown all of the units in the first hidden layer are connected to the input units, all the units in the second hidden layer are connected to the first hidden layer and all the units in the output layer are connected to the second hidden layer). If there are no hidden layers, the output layer is connected directly to the input layer.
You will need to construct the user specified network (based on the options discussed below), train the network using those parameters and then be able to use that network in classification. You will also need to be able to read and write network files. The structure of the network will be given to you by the user in terms of the dataset (which will define the input and output layers) and in the options used to tell you about the hidden layer. The target output vectors can be determined using the routines get_output_vector_size and get_output_vector. You will need to write routines to do similar things to construct an input vector from an example.
The code you will be completing is in the archive smlp.tar.Z To use this code, download the archive to your account and then unpack it as follows:
uncompress smlp.tar.Z tar xvf smlp.tar.Z
This will create the directory student_mlp and a set of files in that directory. The directory includes a makefile that will compile the provided files and produce three programs: train, classify and nfold. Unlike with previous assignments, I can not provide you with simple scripts to run these programs. To run the train program, you will need to provide at least the following arguments:
train -dataset c4.5 <NAMESFILE> <DATAFILE> -save model <MODELFILE> -learn mlp
You may also want to add "-report train predictions". Note that mlp has a number of options (discussed below). To run the classify program, you will need to provide at least the following arguments:
classify -dataset c4.5 <NAMESFILE> <DATAFILE> -use model <MODELFILE> -learn mlp
You may also want to add "-report predictions". To run the nfold program, you will need to provide at least the following arguments:
nfold -dataset c4.5 <NAMESFILE> <DATAFILE> -learn mlp
You may also want to add "-report test predictions".
The options currently available to you in the code are as follows (you can get this information also by simply typing train, classify or nfold with no arguments):
Your code should print out the network weights in a fairly easy to read format when the train routine is run. Something like this would work:
% train -dataset c4.5 bcw.names bcw.data -learn mlp
Bias Unit:
Unit# = 0
Weights from unit: 10 -> (-0.126534) 11 -> (0.265717)
Input Units:
Unit# = 1
Weights from unit: 10 -> (5.342074) 11 -> (-5.891322)
Unit# = 2
Weights from unit: 10 -> (-15.562914) 11 -> (16.727961)
Unit# = 3
Weights from unit: 10 -> (-1.978831) 11 -> (2.071554)
Unit# = 4
Weights from unit: 10 -> (-2.015379) 11 -> (2.151429)
Unit# = 5
Weights from unit: 10 -> (14.482730) 11 -> (-15.744863)
Unit# = 6
Weights from unit: 10 -> (-10.774073) 11 -> (12.032050)
Unit# = 7
Weights from unit: 10 -> (6.528381) 11 -> (-7.228225)
Unit# = 8
Weights from unit: 10 -> (-7.238383) 11 -> (7.770851)
Unit# = 9
Weights from unit: 10 -> (-3.882322) 11 -> (4.183392)
Output Units:
Unit# = 10
Weights into unit: 0 -> (-0.126534) 1 -> (5.342074) 2 -> (-15.562914) 3 -> (-1.978831) 4 -> (-2.015379) 5 -> (14.482730) 6 -> (-10.774073) 7 -> (6.528381) 8 -> (-7.238383) 9 -> (-3.882322)
Unit# = 11
Weights into unit: 0 -> (0.265717) 1 -> (-5.891322) 2 -> (16.727961) 3 -> (2.071554) 4 -> (2.151429) 5 -> (-15.744863) 6 -> (12.032050) 7 -> (-7.228225) 8 -> (7.770851) 9 -> (4.183392)
You can read more about the code you will be completing here. Assume that there is just one output class in your problems.
To complete the provided code you will need to complete four functions (learn, classify, read and write) and the Constructor and Destructor for the class MLP. The skeletons of these functions can be found in the file mlp.C. You will also need to add some fields to the class MLP in the file mlp.h (representing the neural network). A short description of what each function is supposed to do can be found in mlp.C. Hari will give you more details on these functions and answer your questions during lab.
Once you have the basic code completed, you will need to extend the code to include a couple of early stopping methods. Early stopping methods are mechanisms that allow you to stop learning before the maximum number of epochs has been reached. We will add two possible stopping mechanisms:
avg_mse <number>
threshold_ecrit <difference_number> <accuracy_number>
The difference_number requires that the absolute difference for a training
example's output values be less than that threshold before that example
can be considered to be accurately predicted. For example, if this
threshold were 0.1 and the target prediction was 1,0 then 0.92,0.07
would be an allowable prediction (since 0.92 is less than 0.1 from 1
and 0.07 is less than 0.1 from 0) but 0.65,0.31 would not. This threshold
is used to determine how many examples out of the total are predicted
within the difference_number threshold. We then compare this total
to the accuracy_number threshold to see if we can stop. For example,
if there are 100 training examples and 93 of them pass the
difference_number threshold, then we could stop training if the
accuracy_number threshold were 0.9, but we would have to keep going if
it was 0.95.
Conduct experiments to show that an MLP with two units in a single hidden layer can learn the XOR problem (use train to demonstrate this). Report the weights from at least three different runs of the code. Note that you can control the random seed the code is initialized with by using the -seed option. If you do not set the seed manually the seed is set for you using the system clock (and should be fairly random).
Next, conduct experiments on your own datasets. Try to determine an appropriate network structure that allows you good generalization. You should do this using n-fold cross validation (you may want to use a smaller number of folds than 10). Report the weights from your best experiment. Also, show the results from all of your experiments and why you think the network structure you chose is best.
Finally, conduct experiments to determine appropriate parameters for one of the datasets in my public directory (use nfold to do these experiments). I would suggest the breast-cancer-wisconsin dataset, but you may choose any of them. You should conduct experiments to determine a good learning rate, number of epochs, momentum value and network structure. You should try at least 4 different variations of each. Produce a table showing your results and indicate your conclusions about the best values for the various parameters from the results.
Print out a copy of your team's version of the files mlp.h and mlp.C (plus any extra files you add). Also, construct a report of the results of your experiments from the previous section with the results mentioned.
Next your team should write up a short report (at least one page, no more than three) discussing your design decisions in implementing the MLP code and how your version of the code works.
Finally, each member of your team should write a short report (at least a half a page and no more than one page) discussing what you contributed to the effort and how the overall team approach worked for you.