1 2 1 3 1 +
2 1 2 2 2 -
1 2 1 1 2 -
1 1 2 3 1 -
1 2 2 3 2 +
A B C D E Class
-----------------------------------------------------
false true 15 false 20 + positive
true false 1 true 5 - negative
false false 10 true 10 - negative
false false 8 false 15 + positive
true true 13 true 16 + positive
false true 9 false 8 - negative
false false 1 true 5 - negative
true false 12 false 13 - negative
true true 15 false 6 + positive
true true 15 true 10 + positive
false true 13 true 7 - negative
false true 3 false 5 + positive
NOTE:
- What decision tree would be learned using ID3? [20 points]
- For each of the following data points, what class would be predicted
using the 3-Nearest Neighbor algorithm using a Manhattan distance
measure where the two continuous features are scaled to be values
between 0 and 1? [20 points]
- true true 5 true 15
- false true 3 true 9
- false false 15 false 3
- What predictions would be made using the Naive Bayes learning method for the data points shown in the previous question? [20 points]
- Using the agglomerative single link clustering method, determine the clusters that would be produced from the data points above assuming we ignore the class (the - or + value), that our distance is measured as nearest neighbor question above, and where we have the following threshold values (two points are considered to be connected if their distance is *less* than these thresholds): (i) 0.9, (ii) 1.9, and (iii) 2.9. [20 points]
- Explain how ensembles address the issue of overfitting avoidance.
- What is one strength of bagging compared to boosting? Justify your answer.
- Give a brief argument for the use of an ensemble consisting of one decision tree, one support-vector machine (SVM), and one neural network instead of using an ensemble of three models all produced by the same learning algorithm.
A, C -> E B, not C, D -> E E, C -> F not A, D -> F E, F -> G B, not E -> G E, not F -> H E, G, H -> J
ONE->D: 0.0 A->D: 0.5 B->D: 0.0 C->D: -1.0 ONE->E: 0.5 A->E: 0.0 B->E: 0.5 C->E: 0.5 ONE->F: 0.0 D->F: -0.5 E->F: 0.5
What would be the weights after each of the following points is presented (in the sequence shown) assuming a learning rate of 0.25 and a momentum term of 0.9. Assume the hidden and output units use a sigmoidal activation function and that the weights are changed using backpropagation. [20 points]
A B C F
Point 1: 1 0 1 1
Point 2: 0 1 1 0
Point 3: 1 1 1 1
Discuss one key technique (two in total) for addressing the problem of overfitting in (i) decision trees and (ii) neural networks.
A B C D class
-------------------------------------
-1 1 -1 -1 -1
1 1 1 1 1
-1 1 1 1 1
-1 -1 1 1 -1
1 -1 -1 -1 -1
Assuming a linear kernel and the use of slack variables give the set of constraint equations generated for these points. [20 points]
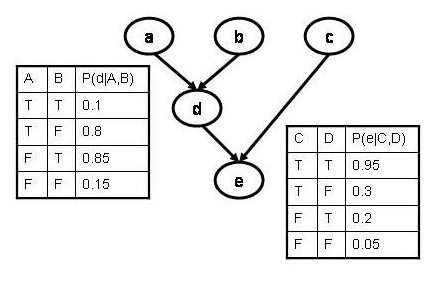
- p(e=true|a=true,b=true,c=true)
- p(d=true|e=true,b=false)
- p(e=false|a=true,c=false)