Language Translation
Language translation is a common aspect of many application programs.
It is the primary function of both assemblers and compilers.
In addition, many programs use languages for representing data that has
a complex structure.
For example, web servers and browsers use HTML and XML for representing
document structures and many graphics display programs use a language
such as PostScript to represent the structure of a graphical
information.
Word processors use a document markup language for representing the
structure of a styled textual document.
Although programs use an internal binary form for representing
information structures, they need to convert the information to a form
suitable for network transfer or file storage.
Language translation is needed to rebuild the internal structures from
files or from network messages.
In its many different forms, language translation software often uses
similar low-level components.
The higher-level components perfom a task called parsing.
Parsing builds an internal representation of the structured information.
This internal representation can be traversed in many ways to perform
the various tasks needed by an application.
Low-Level Components
Language translation usually involves two low-level components.
-
A scanner (or lexical analyser)
A scanner groups characters into tokens, which are
low-level units of meaning in the source text.
-
Symbol tables
A symbol table is used to record information about
identifiers and other forms of reference between different parts
of an information structure.
An identifier is a type of token that is used for naming
variables, types, functions, and procedures.
Scanner
For languages with a textual form, a scanner (or lexical
analyzer) is needed.
It groups characters into tokens, which are low-level units of
meaning in the source code.
Tokens are similar to words and punctuation marks in natural languages.
A scanner typically provides an iterator interface for use by the
parser.
The interface has an implicit current position in the source code text,
which is either at a token or beyond the end of the text.
It provides operations for
-
determining if there is a token at the current position,
-
classifying the token at the current position,
-
retrieving the value of the token at the current position, and
-
advancing the current position.
Scanners will often omit the first operation.
Instead, they return a special end token for the token at the current
position when the current position is beyond the end of the text.
For some languages the scanner may also need to be able to retrieve
tokens beyond the current position without advancing.
This is called look ahead.
Symbol Tables
A symbol table is used to record information about identifiers,
one of the types of tokens in the source code.
Identifiers are use for naming variables, types, and subprograms so the
symbol tables must be capable of recording different kinds of
information.
The symbol tables must be structured to reflect the different kinds of
name scopes in the language.
Block Scopes
Many high-level languages have some form of block structuring which
determines a variety of nested scopes for the identifiers.
Since the meaning of an identifier can depend on the scope, symbol
tables usually organized as a stack of simple tables.
The simple tables are pushed onto the stack when parsing enters a new
scope and popped when parsing leaves a scope.
When information about an identifier is needed, the simple tables are
scanned from top to bottom for entries about the identifier.
The first entry encountered is the one that used.
In short, a Chain of Responsibility design pattern is used, with the
chaining following the nesting.
Types
There are scopes associated with each type in an object-oriented
program in a typed, class-based OOL.
In the following Java code example, there is a scope for the System
class, in which the member out is declared.
Since out is declared to have type PrintStream, there is
another scope for the PrintStream type.
The println() method is defined in this last scope.
System.out.println("Hello, world!");
A compiler uses a symbol table for each of these type scopes.
There is a type table that contains all of these symbol tables as
entries.
The entries are keyed by the type name.
Parsing
Modern language translators often build an internal structural
representation of information.
This representation is called a parse tree.
It is a tree structure in which the children of each node are governed
by a syntax rule.
To understand parse trees, we need to look first at some grammar
definitions.
We will look at definitions for expressions similar to those in C, C++,
and Java.
These definitions could also be used in a program for evaluating
mathematical expressions.
Numeric Expressions
In the following syntax definitions the color red indicates a
token type and the color blue indicates a
nonterminal type.
-
An expression is a sequence of one or more terms
separated by + and
- operators
-
A term is a sequence of one or more factors
separated by *,
/, and %
operators
-
A factor is a one of the following:
-
An identifier-expression
-
A numeric-literal
-
An expression between
( and )
-
A identifier-expression is an
identifier followed by an optional
parameters
-
A parameters is a parameter-list enclosed by
( and )
-
A parameter-list is a sequence of zero or more
expressions separated by ,s
Statements
In the following syntax definitions the color red indicates a
token type and the color blue indicates a
nonterminal type.
These definitions are far from complete.
-
A statement is one of the following:
-
A block-statement
-
An assignment-statement
-
An if-statement
-
A while-statement
-
A for-statement
-
A switch-statement
-
A break-statement
-
A continue-statement
-
A return-statement
-
A block-statement is a sequence of statements
between { and }
-
A while-statement has the following form:
-
while
parenthesized-expression statement
Parse Trees
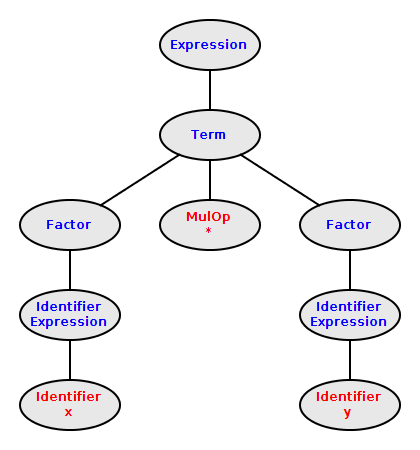
Parse Tree for a A Simple Expression
A parse tree is a structural representation of a particular source
text as interpreted in a specific grammar.
It has node types for each type of grammar component in the
language.
Each subtree corresponds to a structural component of the source
code.
There are two general types of nodes.
-
Leaves -
The leaves of a parse tree are tokens from the source text.
They are Leaves in the Composite design pattern and
TerminalExpressions in the Interpreter design pattern.
-
Interior Nodes -
The interior nodes of a parse tree are roots of subtrees
corresponding to higher-level structures in the source text.
The type of an interior node indicates the grammar rule that
governs the children of that node.
Interior nodes are Composites in the Composite design pattern
and NonterminalExpressions in the Interpreter design pattern.
The diagram to the left shows a simple parse tree for the simple
expression x*y.
Leaves (tokens) are shown in red and interior nodes are shown in
blue.
Parse Tree Construction
Construction of parse tree nodes in the numeric expressions grammar
are shown along with diagrams showing typical partial parse trees.
In this example, there is a Java class for each type of parse tree node.
The constructor for a class just builds one node, invoking other
constructors to get its children.
Each constructor has a scanner parameter.
The constructor has the side-effect of advancing the position of the
scanner past the text used to construct the node.
Node constructors usually interpret grammar rules in a greedy way.
They consume as much text as possible consistent with their grammar
rules.
Constructing Expression Nodes
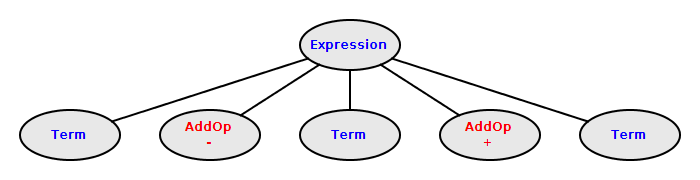
An expression is a sequence of one or more terms
separated by + and
- operators
public Expression(Scanner scanner) {
Term term = new Term(scanner);
addChild(term);
Token operator = scanner.getToken();
String type = operator.getType();
while (type.equals("+") || type.equals("-")) {
addChild(operator);
scanner.advance();
term = new Term(scanner);
addChild(term);
operator = scanner.getToken();
type = operator.getType();
}
}
Constructing Term Nodes
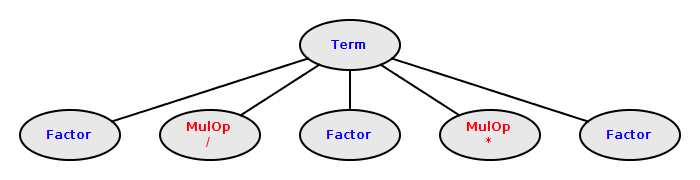
A term is a sequence of one or more factors
separated by *,
/, and %
operators
public Term(Scanner scanner) {
Factor factor = new Factor(scanner);
addChild(factor);
Token operator = scanner.getToken();
String type = operator.getType();
while (type.equals("*") || type.equals("/") || type.equals("%")) {
addChild(operator);
scanner.advance();
factor = new Factor(scanner);
addChild(factor);
operator = scanner.getToken();
type = operator.getType();
}
}
Constructing Factor Nodes
Some Typical Factors
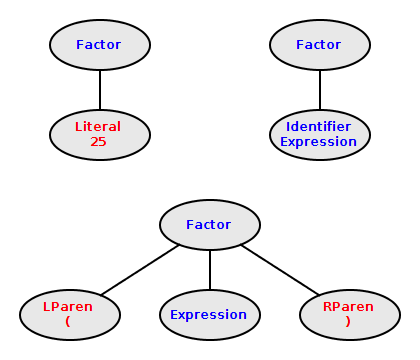
A factor is a one of the following:
-
An identifier-expression
-
A numeric-literal
-
An expression between
( and )
public Factor(Scanner scanner) {
Token firstToken = scanner.getToken();
String firstType = firstToken.getType();
if (firstType.equals("identifier")) {
addChild(new IdentifierExpression(scanner));
} else if (firstType.equals("numeric-literal")) {
addChild(firstToken);
scanner.advance();
} else if (firstType.equals("(")) {
addChild(firstToken);
scanner.advance();
addChild(new Expression(scanner));
Token lastToken = scanner.getToken();
String lastType = lastToken.getType();
if (lastType.equals(")")) {
addChild(lastToken);
scanner.advance();
} else {
// handle error
}
} else {
// handle error
}
}
Constructing IdentifierExpression Nodes
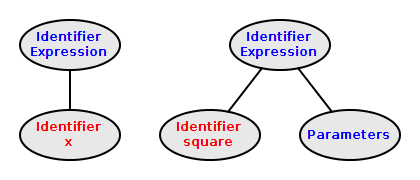
A identifier-expression is an
identifier followed by an optional
parameters
public IdentifierExpression(Scanner scanner) {
Token identifier = scanner.getToken();
addChild(identifier);
scanner.advance();
Token nextToken = scanner.getToken();
String nextType = nextToken.getType();
if (nextType.equals("(")) {
addChild(new ParameterList(scanner));
}
}
Constructing Parameters Nodes
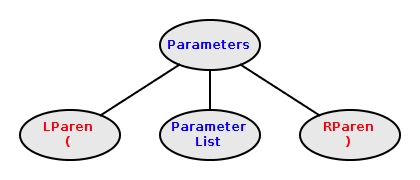
A parameters is a parameter-list enclosed by
( and )
public Parameters(Scanner scanner) {
Token lparens = scanner.getToken();
addChild(lparens);
scanner.advance();
addChild(new ParameterList(scanner));
Token rparens = scanner.getToken();
String nextType = rparens.getType();
if (nextType.equals(")")) {
addChild(rparens);
scanner.advance();
} else {
// handle error
}
}
Constructing ParameterList Nodes
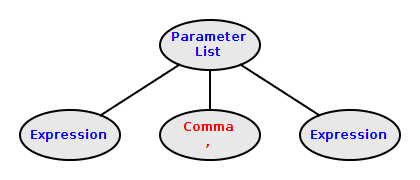
A parameter-list is a sequence of zero or more
expressions separated by ,s
public ParameterList(Scanner scanner) {
Token nextToken = scanner.getToken();
String nextType = nextToken.getType();
if (nextType.equals(")")) {
return;
}
addChild(new Expression(scanner));
nextToken = scanner.getToken();
nextType = nextToken.getType();
while (nextType.equals(",")) {
addChild(nextToken);
scanner.advance();
addChild(new Expression(scanner));
nextToken = scanner.getToken();
nextType = nextToken.getType();
}
}