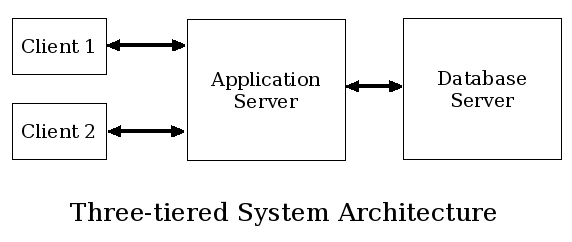
Many modern web applications are connected to external databases via a tiered system architecture:
Most modern databases are managed using Structured Query Language (SQL), which we describe here.
Many modern web applications are connected to external databases via a tiered system architecture:
Most modern databases are managed using Structured Query Language (SQL), which we describe here.
Structured Query Language (SQL) is a standard interactive and programming language for getting information from and updating a relational database.
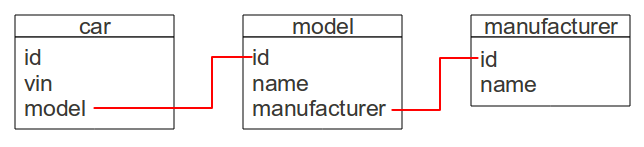
A relational database is composed of tables, each containing data about a particular type of entity. The data in a table is organized into rows and columns.
Each row represents a single entity. New rows are easily added to a table.
Each column represents a typed attribute of the entities. For example a table of automobiles might have 3 columns:
<vin, model, manufacturer>
The collection of rows in a table constitutes a relation.
SQL is a command language that lets you create tables, insert rows into tables, query table contents, and update table data.
CREATE TABLE name (col1 type1, col2 type2, ...);
where name is the name of the table, coli is the name of the ith column, and typei is the type of data in coli.
Note: Keywords are shown in upper-case for clarity, although case is ignored for keywords.
Here is a command creating a (empty) table of, say, car manufacturers:
It specifies a table called manufacturer with a column of identifying numbers and a column of names.
Note that SQL identifiers can be delimited by double quotation marks, although they are not part of the identifier.
| SQL Type | Description | Java Type |
|---|---|---|
| INTEGER | 32-bit integer | java.lang.Integer |
| DOUBLE | 64-bit double precision floating point | java.lang.Double |
| CHAR(N) | Fixed size string of length N | java.lang.String |
| VARCHAR(N) | Variable size string of up to length N | java.lang.String |
| DATE | Date in yyyy-mm-dd format | java.sql.Date |
| BLOB | Binary Large Object (e.g. image) | java.sql.Blob |
| CLOB | Character Large Object (e.g. text) | java.sql.Clob |
Tables often have a column that acts as a primary key, or value that uniquely identifies each row in the table so that it can be used for indexing.
For example, the id column in the manufacturer table might fulfill that role (although in this case the name column may also work).
To specify that a column is a primary key, the CREATE TABLE command requires a column constraint.
Here are some column constraints that are often associated with primary keys:
| Constraint | Meaning |
|---|---|
| PRIMARY KEY | This column serves as the table's primary key |
| NOT NULL | No row in the table can have a null value in this column |
| GENERATED ALWAYS AS IDENTITY | This column (which must be of integer type) will have a unique value automatically generated whenever a row is inserted |
Here is the manufacturer table created using these constraints:
INSERT INTO table (col1, col2, ...)
VALUES (value1, value2, ...);
where table is the name of the table, and each column coli in the row gets value valuei.
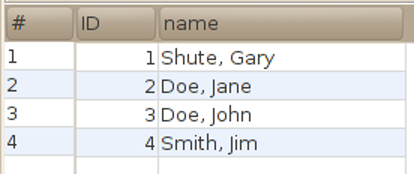
Here are commands that insert three rows in the manufacturer table:
Note that the primary key id is left out since it is generated automatically.
Note also that there are two types of string literals:A database query retrieves information from one or more tables.
Basic syntax for one table:
SELECT column1, column2, ... FROM table;
SELECT * FROM table;
SELECT column1, column2, ... FROM table
WHERE condition;
* is a wildcard that stands for all columns in the table.
The SELECT statement creates and returns another table.| Statement | Table Created |
|---|---|
| SELECT "name" FROM manufacturer; | 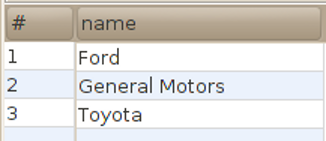 |
| SELECT * FROM manufacturer; | 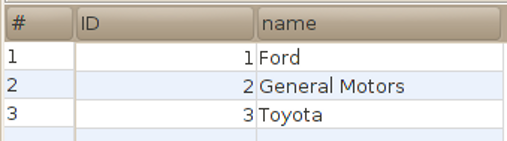 |
| SELECT id FROM manufacturer WHERE "name" = 'Toyota'; |
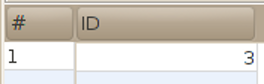 |
Two common operations that modify tables are to update columns within a row, and to delete a row (or rows) entirely.
UPDATE table SET column = value WHERE condition;
DELETE FROM table WHERE condition;
| Statement | Effect |
|---|---|
| SELECT * FROM manufacturer; | |
| UPDATE manufacturer SET "name" = 'Mazda' WHERE id = 3; |
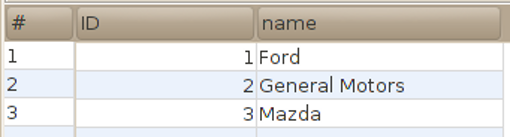 |
| DELETE FROM manufacturer WHERE id = 2; |
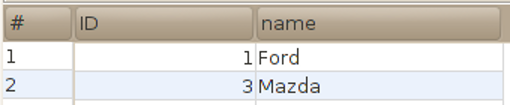 |
Most non-trivial database applications have more than one table, with dependency relationships among them.
This section describes how tables can contain information from other tables, and how to avoid data integrity problems that can result.Suppose we want to add car model information, for example, the Camry model built by Toyota, to the database.
We could create a new model table like this:
But then it would duplicate information (manufacturer's name) already in the manufacturer table.Instead we can let the manufacturer column contain a manufacturer id, which is an integer:
with the intent that the model table's manufacturer column refer to the manufacturer table's id:
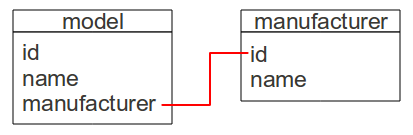
While this would work, it could result in the database being corrupted. Consider the following scenario:
| Statement | Effect |
|---|---|
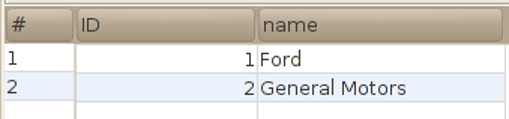
| SELECT * FROM manufacturer; | |
| INSERT INTO model ("name", manufacturer) VALUES ('Camry', 3); SELECT * FROM model; |
 |
| DELETE FROM manufacturer WHERE id = 3; SELECT * FROM manufacturer; |
 |
If the database management system (DBMS) knows that a column in one table references a column in another, it can refuse to delete rows that would result in dangling references.
We can declare that a column in one table contains the same information as another table's key using a foreign key constraint:
FOREIGN KEY (column1) REFERENCES table (column2)
where:
Here is the model table created with a foreign key:
Note that a foreign key declaration is a table-level constraint, and is not included within a column declaration.In order to populate the model table, we need the id numbers of manufacturers.
One approach is to hard-code them in INSERT statements:
Drawbacks:Instead we can look up the id of a manufacturer using a subquery:
Note: The FETCH FIRST ROW ONLY clause is recognized in Apache Derby from version 10.6 on. For earlier versions the clause can be dropped.Sometimes the information required by a query lies in more than one table.
This section describes how to include multiple tables in a SELECT statement.Suppose we want to retrieve car model information.
We could select all the columns from the model table using:
This yields:
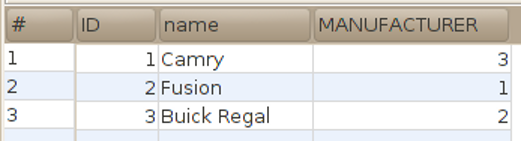
We would prefer to get the manufacturer's name, rather than id.
However, the manufacturer's name is in the manufacturer table.Here are the contents of the model and manufacturer tables:
| model | manufacturer |
|---|---|
|
|
Suppose we were to include them both in a SELECT statement:
Each row of the created table is composed of a row from one table joined with a row from the other.
All possible joins of rows are performed.
Since each of these tables has 3 rows, their table join has 3 × 3 = 9 rows.
So the statement above yields:
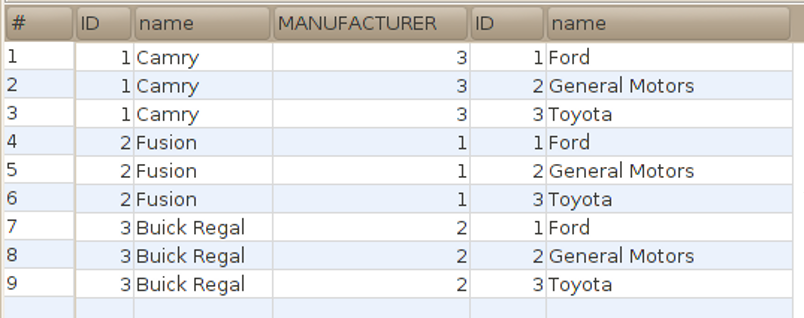
Many of the rows in the table join have irrelevant information, since they join car models with the wrong manufacturers.
However, some rows, namely, those where the model table's manufacturer column matches the manufacturer table's id column, are relevant.
We can select only these rows using selection criteria:
This statement yields:

You can name columns specified in SELECT statements with an AS clause.
These names act as aliases for actual table column names in the retrieved table.
Instead of:
we can use:
Note that we disambiguate the column names by using the "table.column" syntax.
This will produce:
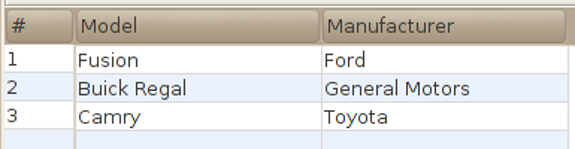
This section gives more examples of table creation, table population, and table queries by extending the car database.
Tables are added to describe cars and car ownership.A car is described by its vehicle identification number (vin) and its model.
This section shows how to create, populate, and view a car table.We would like to view a car's vin, model, and manufacturer:
Note that this query joins three tables.
Since the car table has two rows, the table join has 2 × 3 × 3 = 18 rows.
With the selection criteria and AS clauses, the query produces:

Typically, persons own cars, so representing car ownership in database tables will involve representing persons.
This section describes a naive way of representing ownership and then a better way.A naive way of representing car ownership is to define a person table and give it an external reference to the car table:

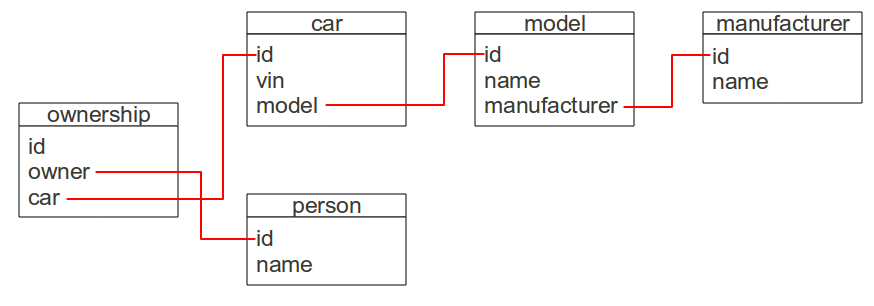
For this database a person is described by just his or her name.
This section shows how to create, populate, and view a person table.For each owner relationship, we would like to view the owner's name, the car's model name, and the car's vin.
This requires joining four tables:
This query produces:

SQL has five important types of statements:
Most databases have multiple tables. They frequently use foreign keys to allow data from one table to be referenced form another table. This is important for two reasons:
Foreign key constraints can be placed on tables to ensure that deleting rows from one table does not result in dangling references in another table.